Una conferenza per sviluppatori sul Gurten
La Uphill Conf 2026 si è tenuta il 7 e 8 maggio sul Gurten, sopra Berna. Secondo la presentazione ufficiale, l'evento è pensato per sviluppatori software e si concentra su IA/ML pratiche in produzione: costruire prodotti AI-nativi, mettere in sicurezza le applicazioni LLM, sistemi agentici, inferenza a costi sostenibili. Il programma di quest'anno includeva interventi di Google DeepMind, AWS, Hugging Face e IBM Research, oltre al keynote per cui eravamo lì.
Apertus è il large language model interamente aperto, costruito in Svizzera, che alimenta ogni traduzione prodotta da Helvetra. Quando il co-lead del progetto annuncia cosa arriverà dopo, noi ascoltiamo.
Il keynote
Venerdì mattina Imanol Schlag, AI Research Scientist all'ETH AI Center e co-lead del progetto Apertus, ha aperto la giornata con «Apertus: Democratizing Open and Compliant LLMs For Global Language Environments» (pagina del talk).
Era il tipo di intervento che mette tutto insieme in 30 minuti. Cos'è Apertus, perché è strutturato così, dove si colloca nel panorama globale e cosa arriverà dopo. Le slide qui sotto provengono dalla sessione stessa.

Perché «fully open» non è solo uno slogan
La distinzione conta. Un modello open-weight permette di scaricare il file e farlo girare sul proprio hardware: utile, ma non si sa ancora su cosa sia stato addestrato, chi abbia curato i dati, come sia stato allineato. Un modello fully open pubblica tutto: i dati di addestramento e la pipeline per riprodurli, il codice di addestramento, i checkpoint del modello lungo tutto il training, e un report tecnico di oltre 100 pagine. L'organizzazione GitHub di Apertus ospita il tutto.
Schlag l'ha reso concreto con una tabella comparativa che vale la pena riportare:
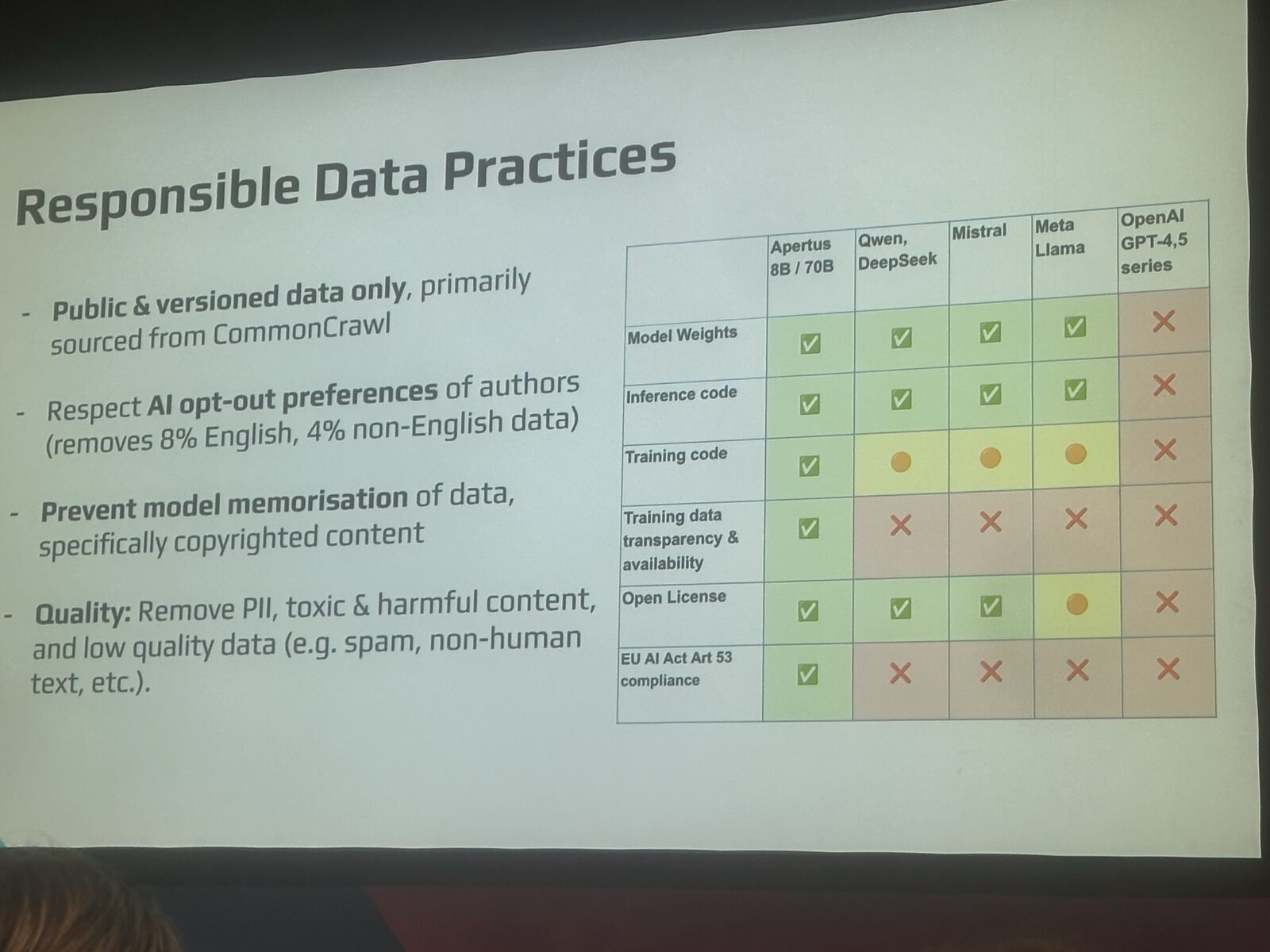
Non è un'affermazione di marketing. L'articolo 53 dell'AI Act europeo impone ai fornitori di IA di uso generale di pubblicare «un riassunto sufficientemente dettagliato dei contenuti di addestramento». Come ha sottolineato Schlag durante il talk: «Per quanto ne so, nessun modello closed o open-weight soddisfa davvero questo requisito.» Apertus invece sì.
Il team ha anche rifiutato categoricamente di scrapare contenuti piratati. Rispetta i segnali di AI opt-out (le direttive IA in stile robots.txt), il che costa circa l'8% dei dati di addestramento in inglese e il 4% dei dati non in inglese. Un prezzo che erano felici di pagare. Sono andati oltre: Schlag ha descritto un metodo esplicito anti-memorizzazione nella pipeline di addestramento, perché il modello non possa restituire passaggi protetti da copyright visti durante l'addestramento. Nessuno dei grandi laboratori closed pubblica nulla di paragonabile.
Il momento del tedesco svizzero
Ecco la parte del talk più importante per chi usa Helvetra.
Apertus 1 è uscito a settembre 2025. Il primo passaggio di post-training (il fine-tuning supervisionato che insegna al foundation model a comportarsi in modo conversazionale) non includeva alcun dato in tedesco svizzero. Il modello si rifiutava semplicemente di parlare tedesco svizzero perché ne aveva visto pochissimo durante l'instruction tuning.
E poi, con le parole stesse di Schlag:
«Visto che abbiamo una base multilingue molto forte e molte altre lingue alemanniche nei dati di addestramento, è bastato a un dottorando forse un giorno per mettere insieme qualche migliaio di esempi conversazionali in tedesco svizzero, di cui circa la metà generati in modo sintetico, per portare le prestazioni da praticamente zero a, diciamolo onestamente, il 50–40%. Quindi non è chiaramente straordinario, ma la cosa straordinaria è quanto siamo arrivati lontano con così poco lavoro.»
Rileggetelo con calma. Un dottorando. Un giorno. Qualche migliaio di esempi, metà sintetici. Da zero a circa il 40% di prestazioni in tedesco svizzero.
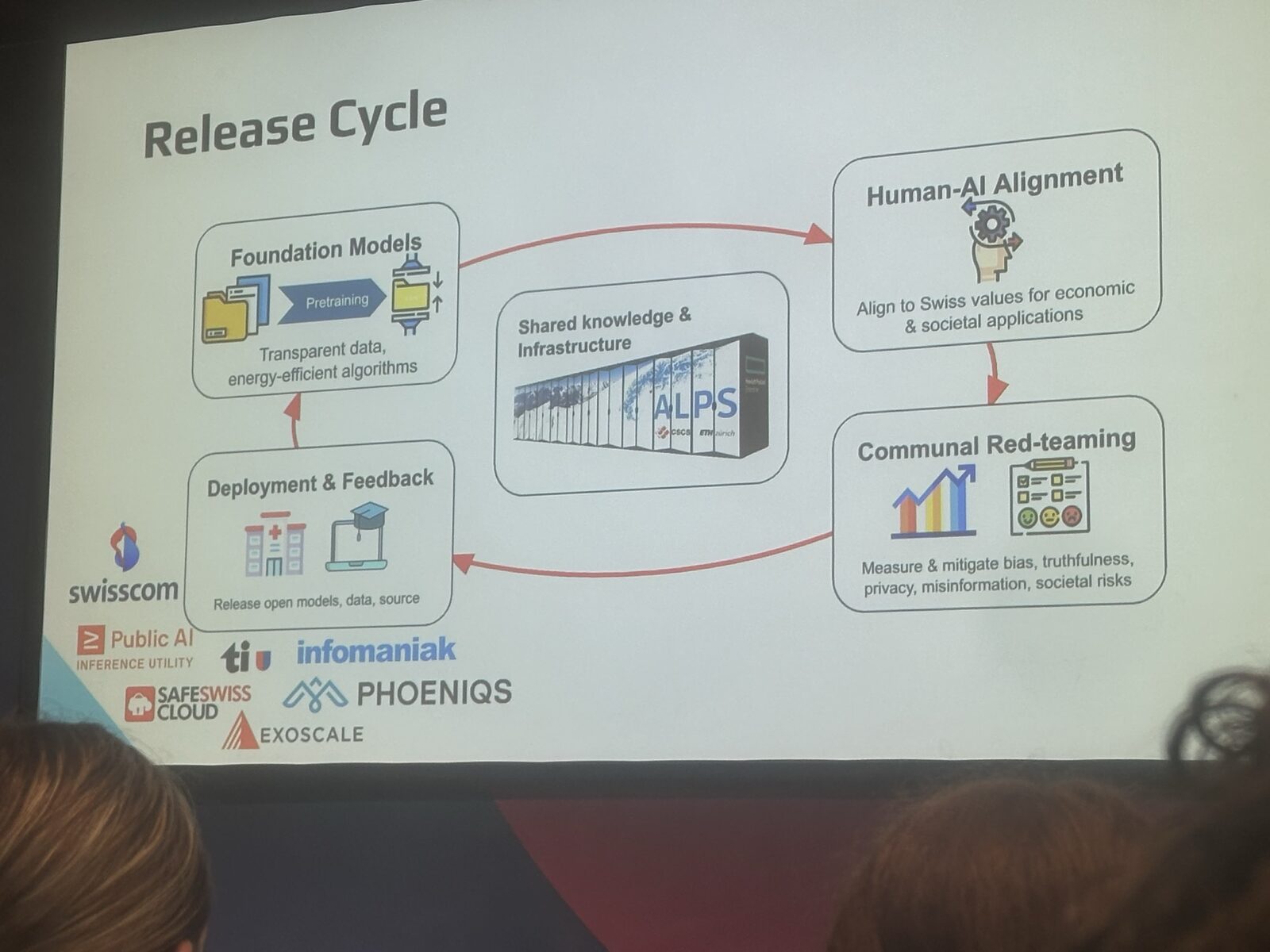
Schlag è stato onesto: il 40% non è ancora eccezionale. Ma il punto è la traiettoria. Un foundation model abbastanza solido da portare una lingua poco rappresentata a quel livello in una sola giornata di post-training è un modello che continuerà a migliorare parecchio sul tedesco svizzero man mano che il team ci investe. E il team ci sta investendo. Apertus 1.5 è in post-training proprio adesso; Apertus 2 è in progettazione su una scala molto più ampia.
Ogni volta che Apertus migliora, Helvetra migliora automaticamente. È il patto che abbiamo accettato quando abbiamo scelto un modello svizzero fully open come motore.
Cosa arriverà dopo
Il deployment ticinese che Schlag ha menzionato di passaggio merita uno sguardo più approfondito, perché è finora l'uso più concreto di Apertus nel settore pubblico. Secondo CSCS (marzo 2026), il Centro sistemi informativi (CSI) del Cantone, all'interno del Dipartimento delle finanze e dell'economia, sta lanciando uno strumento di traduzione interno costruito su Apertus da una startup affiliata all'USI chiamata Artificialy, cofondata da Luca Gambardella (Professore di IA all'Università della Svizzera italiana). Una fase di test con circa 100 dipendenti cantonali parte nelle prossime settimane. Notevolmente, CSCS riferisce che Apertus 8B ha raggiunto un punteggio benchmark del 94% dopo il fine-tuning per quello specifico compito di traduzione. Un dato utile su come il modello Apertus più piccolo si comporta quando viene ottimizzato su un carico di lavoro reale.
Dal talk sono emersi due punti concreti di roadmap:
Apertus 1.5 è in addestramento mentre scriviamo. Si tratta di un pre-training continuato del checkpoint precedente con capacità di input immagini e audio (la vision è matura, l'audio per ora più sperimentale), e di una pipeline di reinforcement learning per ragionamento, codice e uso di strumenti. Schlag era visibilmente entusiasta dei primi risultati sulla vision, e il team condividerà di più non appena sarà pronto.
Apertus 2 è un'ambizione più ampia: colmare il divario con i più grandi modelli open-weight, che ora si collocano tra 500 miliardi e mille miliardi di parametri. L'attuale Apertus 70B è stato progettato deliberatamente per eguagliare il Llama 3 70B originale come prova di capacità. Il team ora vuole vedere quanto in alto possa spingersi sul supercomputer Alps di CSCS (il più grande cluster pronto per l'IA gestito da un'istituzione pubblica al mondo), restando dentro gli standard di trasparenza che si è dato.
Perché restiamo su Apertus

Abbiamo fatto la stessa scommessa, nella nostra dimensione. Helvetra è ancorata a un solo modello, Apertus, per le stesse ragioni elencate da Schlag. I dati restano in Svizzera, la storia di addestramento è riproducibile, l'allineamento è trasparente, e il modello è governato da istituzioni pubbliche svizzere, non da azionisti americani. Non abbiamo in programma un «selettore di LLM» né di passare in silenzio a quello che costa meno questo trimestre. Più dettagli su questa scommessa qui.
Il compromesso è onesto. Apertus 1 ha delle lacune, soprattutto sul tedesco svizzero. Le sentiamo quando traduciamo, voi le sentite quando leggete il risultato. Ma il talk sul Gurten di questo mese è stato un forte promemoria del fatto che il divario si sta chiudendo, in fretta, in pubblico, da parte di un team che ci dice esattamente come lo sta facendo. La prossima volta che Apertus uscirà, Helvetra uscirà con lui.
Risorse
- Sito del progetto Apertus: apertvs.ai (in precedenza apertus-ai.org)
- Swiss AI Initiative (ombrello): swiss-ai.org
- Apertus su Hugging Face: huggingface.co/swiss-ai
- Apertus su GitHub: github.com/swiss-ai
- Pagina del talk: Uphill Conf, keynote Apertus
- Uphill Conf 2026: uphillconf.com
- L'infrastruttura: supercomputer Alps di CSCS
- Il deployment ticinese: CSCS: Apertus powers in-house AI translation for Ticino (marzo 2026)