Eine Entwicklerkonferenz auf dem Gurten
Die Uphill Conf 2026 fand am 7. und 8. Mai auf dem Gurten oberhalb von Bern statt. Gemäss der Selbstbeschreibung der Konferenz richtet sich der Anlass an Software-Entwickler und konzentriert sich auf praxisnahe KI und ML im produktiven Einsatz: KI-native Produkte bauen, LLM-Anwendungen absichern, agentische Systeme, kosteneffiziente Inferenz. Das diesjährige Programm umfasste Vorträge von Google DeepMind, AWS, Hugging Face und IBM Research, neben der Keynote, für die wir gekommen waren.
Apertus ist das in der Schweiz entwickelte, vollständig offene Large Language Model, das jede von Helvetra erzeugte Übersetzung antreibt. Wenn der Co-Lead des Projekts ankündigt, was als Nächstes kommt, hören wir hin.
Die Keynote
Am Freitagmorgen eröffnete Imanol Schlag, AI Research Scientist am ETH AI Center und Co-Lead des Apertus-Projekts, den Tag mit «Apertus: Democratizing Open and Compliant LLMs For Global Language Environments» (Vortragsseite).
Es war eine dieser Präsentationen, die in 30 Minuten alles zusammenbringen. Was Apertus ist, warum es so aufgebaut ist, wo es im globalen Umfeld steht, und was als Nächstes kommt. Die Folien unten stammen aus der tatsächlichen Session.

Warum «fully open» nicht nur ein Slogan ist
Der Unterschied ist wichtig. Ein open-weight Modell können Sie herunterladen und auf eigener Hardware betreiben. Nützlich, aber Sie wissen immer noch nicht, womit es trainiert wurde, wer die Daten kuratiert hat, wie es ausgerichtet wurde. Ein fully open Modell veröffentlicht das alles: die Trainingsdaten und die Pipeline zu ihrer Reproduktion, den Trainingscode, Model-Checkpoints aus dem gesamten Trainingsverlauf, sowie einen technischen Bericht von über 100 Seiten. Die Apertus-GitHub-Organisation hostet das Ganze.
Schlag hat das mit einer Vergleichstabelle konkret gemacht, die wir hier wiedergeben:
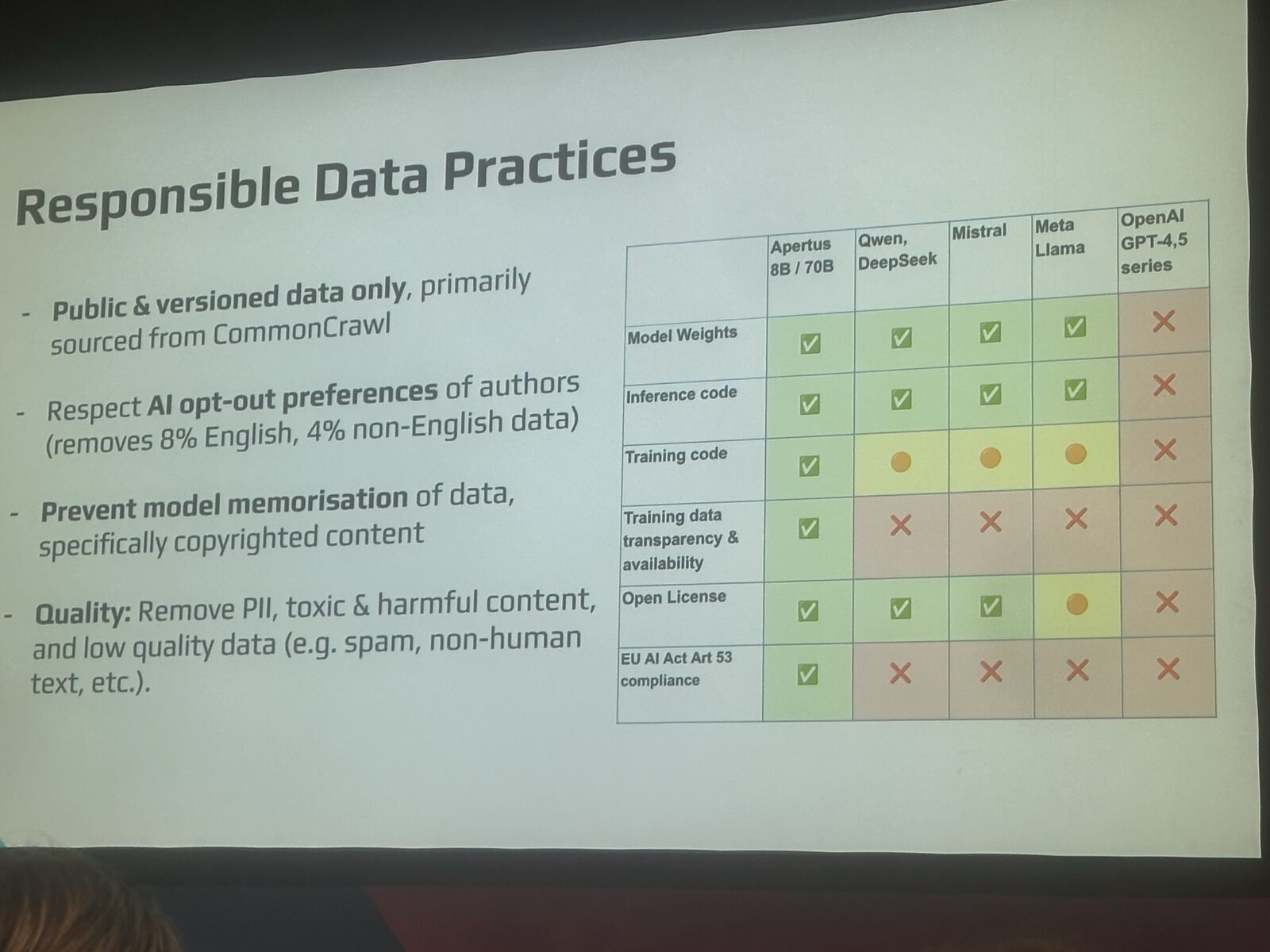
Das ist keine Marketingaussage. Artikel 53 des EU AI Act verlangt von Anbietern allgemeiner KI-Modelle, «eine ausreichend detaillierte Zusammenfassung der Trainingsinhalte» zu veröffentlichen. Schlag wies in seinem Vortrag darauf hin: «Soweit ich weiss, erfüllt kein Closed- oder Open-Weight-Modell diese Anforderung tatsächlich.» Apertus tut es.
Das Team hat sich auch kategorisch geweigert, raubkopierte Inhalte zu crawlen. Es respektiert AI-Opt-out-Signale (die KI-Direktiven nach Art von robots.txt), was etwa 8 Prozent der englischen Trainingsdaten und 4 Prozent der nicht-englischen Daten kostet. Ein Preis, den das Team gerne gezahlt hat. Es ging noch weiter: Schlag beschrieb eine explizite Methode gegen Memorisierung in der Trainings-Pipeline, damit das Modell urheberrechtlich geschützte Passagen, die es im Training gesehen hat, nicht wiedergeben kann. Keines der grossen Closed-Labs veröffentlicht etwas Vergleichbares.
Der Moment für Schweizerdeutsch
Hier kommt der Teil des Vortrags, der für die Helvetra-Nutzerinnen und -Nutzer am wichtigsten war.
Apertus 1 wurde im September 2025 veröffentlicht. Im ersten Post-Training-Schritt (das überwachte Feintuning, das dem Foundation Model beibringt, sich konversationell zu verhalten) waren null Schweizerdeutsch-Daten enthalten. Das Modell weigerte sich schlicht, Schweizerdeutsch zu sprechen, weil es im Instruction-Tuning kaum welches gesehen hatte.
Und dann, in Schlags eigenen Worten:
«Weil wir ein so starkes multilinguales Fundament und viele andere alemannische Sprachen in den Trainingsdaten haben, hat es einen Doktoranden vielleicht einen Tag gekostet, ein paar Tausend Schweizerdeutsch-Konversationsbeispiele zusammenzustellen, davon etwa die Hälfte synthetisch generiert, um die Leistung von praktisch null auf, ehrlich gesagt, 50–40 Prozent zu bringen. Das ist natürlich nicht überragend, aber das Erstaunliche ist, wie weit es mit so wenig Aufwand kam.»
Lesen Sie das in Ruhe. Ein Doktorand. Ein Tag. Ein paar Tausend Beispiele, davon die Hälfte synthetisch. Von null auf rund 40 Prozent Schweizerdeutsch-Leistung.
Schlag war ehrlich: 40 Prozent sind noch nicht beeindruckend. Aber es geht um die Richtung. Ein Foundation Model, das stark genug ist, eine ressourcenarme Sprache an einem einzigen Tag Post-Training auf dieses Niveau zu bringen, ist ein Foundation Model, das mit jedem zusätzlichen Aufwand des Teams beim Schweizerdeutsch deutlich besser wird. Und das Team legt nach. Apertus 1.5 befindet sich gerade im Post-Training; Apertus 2 wird in einem deutlich grösseren Massstab entworfen.
Jedes Mal, wenn Apertus besser wird, wird Helvetra automatisch besser. Das ist die Vereinbarung, der wir zugestimmt haben, als wir uns für ein fully open Schweizer Modell als unsere Engine entschieden haben.
Was als Nächstes kommt
Der Einsatz im Tessin, den Schlag nebenbei erwähnte, ist einen genaueren Blick wert, weil er bislang die konkreteste Nutzung von Apertus im öffentlichen Sektor darstellt. Laut CSCS (März 2026) rollt das Centro sistemi informativi (CSI) des Kantons, angesiedelt im Departement für Finanzen und Wirtschaft, ein hauseigenes Übersetzungswerkzeug aus, das von einem USI-nahen Startup namens Artificialy auf Apertus aufgebaut wurde. Mitgegründet wurde Artificialy von Luca Gambardella (Professor für KI an der Università della Svizzera italiana). Eine Testphase mit rund 100 Kantonsangestellten startet in den kommenden Wochen. Bemerkenswert: CSCS berichtet, dass Apertus 8B nach dem Fine-Tuning für diese spezifische Übersetzungsaufgabe einen Benchmark-Wert von 94 Prozent erreicht hat. Ein aussagekräftiger Datenpunkt dazu, wie das kleinere Apertus-Modell auf eine konkrete Aufgabe abgestimmt abschneidet.
Zwei konkrete Roadmap-Punkte kamen aus dem Vortrag:
Apertus 1.5 wird, während wir das schreiben, gerade trainiert. Es handelt sich um ein fortgesetztes Pre-Training des vorigen Checkpoints mit Bild- und Audio-Input-Fähigkeiten (Vision ist ausgereift, Audio vorerst experimenteller) sowie einer Reinforcement-Learning-Pipeline für Reasoning, Code und Tool Use. Schlag war sichtlich begeistert von ersten Vision-Ergebnissen, und sie werden mehr teilen, sobald es so weit ist.
Apertus 2 ist die grössere Ambition: die Lücke zu den grössten open-weight Modellen schliessen, die mittlerweile zwischen 500 Milliarden und einer Billion Parameter liegen. Das aktuelle Apertus 70B wurde bewusst so ausgelegt, das ursprüngliche Llama 3 70B als Fähigkeitsnachweis zu erreichen. Das Team will nun ausloten, wie weit es auf dem Alps-Supercomputer von CSCS gehen kann (dem grössten AI-ready Hochleistungsrechner einer öffentlichen Institution weltweit), und dabei innerhalb der eigenen Transparenzstandards bleiben.
Warum wir bei Apertus bleiben

Wir haben in unserer Grössenordnung die gleiche Wette gemacht. Helvetra ist auf ein einziges Modell, Apertus, ausgerichtet, aus den gleichen Gründen, die Schlag aufgezählt hat. Die Daten bleiben in der Schweiz, die Trainingsgeschichte ist reproduzierbar, das Alignment ist transparent, und das Modell wird von Schweizer öffentlichen Institutionen geführt, nicht von amerikanischen Aktionären. Wir planen keinen «LLM-Picker» und kein stilles Wechseln auf das, was dieses Quartal am günstigsten ist. Mehr zu dieser Wette hier.
Der Trade-off ist ehrlich. Apertus 1 hat Lücken, vor allem beim Schweizerdeutsch. Wir spüren sie beim Übersetzen, Sie spüren sie beim Lesen der Ausgabe. Aber der Vortrag auf dem Gurten in diesem Monat war eine starke Erinnerung daran, dass sich diese Lücke schliesst, schnell, in der Öffentlichkeit, durch ein Team, das uns genau erklärt, wie es das macht. Wenn Apertus das nächste Mal ausliefert, liefert Helvetra mit.
Ressourcen
- Apertus-Projektseite: apertvs.ai (vormals apertus-ai.org)
- Swiss AI Initiative (Dach): swiss-ai.org
- Apertus auf Hugging Face: huggingface.co/swiss-ai
- Apertus auf GitHub: github.com/swiss-ai
- Vortragsseite: Uphill Conf, Apertus-Keynote
- Uphill Conf 2026: uphillconf.com
- Die Infrastruktur: CSCS Alps Supercomputer
- Der Tessiner Einsatz: CSCS: Apertus powers in-house AI translation for Ticino (März 2026)