Une conférence pour développeurs sur le Gurten
La Uphill Conf 2026 s'est tenue les 7 et 8 mai sur le Gurten, au-dessus de Berne. Selon la présentation de la conférence, l'événement s'adresse aux développeurs et se concentre sur l'IA/ML pratique en production: créer des produits AI-natifs, sécuriser les applications de LLM, les systèmes agentiques, l'inférence à coût maîtrisé. Le programme de cette année comprenait des interventions de Google DeepMind, AWS, Hugging Face et IBM Research, en plus de la keynote pour laquelle nous étions venus.
Apertus est le grand modèle de langage entièrement ouvert, conçu en Suisse, qui propulse chaque traduction produite par Helvetra. Quand le co-lead du projet annonce la suite, nous écoutons.
La keynote
Vendredi matin, Imanol Schlag, AI Research Scientist au ETH AI Center et co-lead du projet Apertus, a ouvert la journée avec «Apertus: Democratizing Open and Compliant LLMs For Global Language Environments» (page du talk).
C'était le genre de présentation qui réunit tout en 30 minutes. Ce qu'est Apertus, pourquoi il est structuré ainsi, où il se situe dans le paysage mondial, et ce qui arrive ensuite. Les diapositives ci-dessous proviennent de la session elle-même.

Pourquoi «fully open» n'est pas qu'un slogan
La distinction compte. Un modèle open-weight vous permet de télécharger le fichier et de le faire tourner sur votre matériel: utile, mais vous ne savez toujours pas sur quoi il a été entraîné, qui a curé les données, comment il a été aligné. Un modèle fully open publie tout: les données d'entraînement et le pipeline pour les reproduire, le code d'entraînement, les checkpoints du modèle tout au long de l'entraînement, et un rapport technique de plus de 100 pages. L'organisation GitHub Apertus héberge l'ensemble.
Schlag l'a rendu concret avec un tableau comparatif que voici:
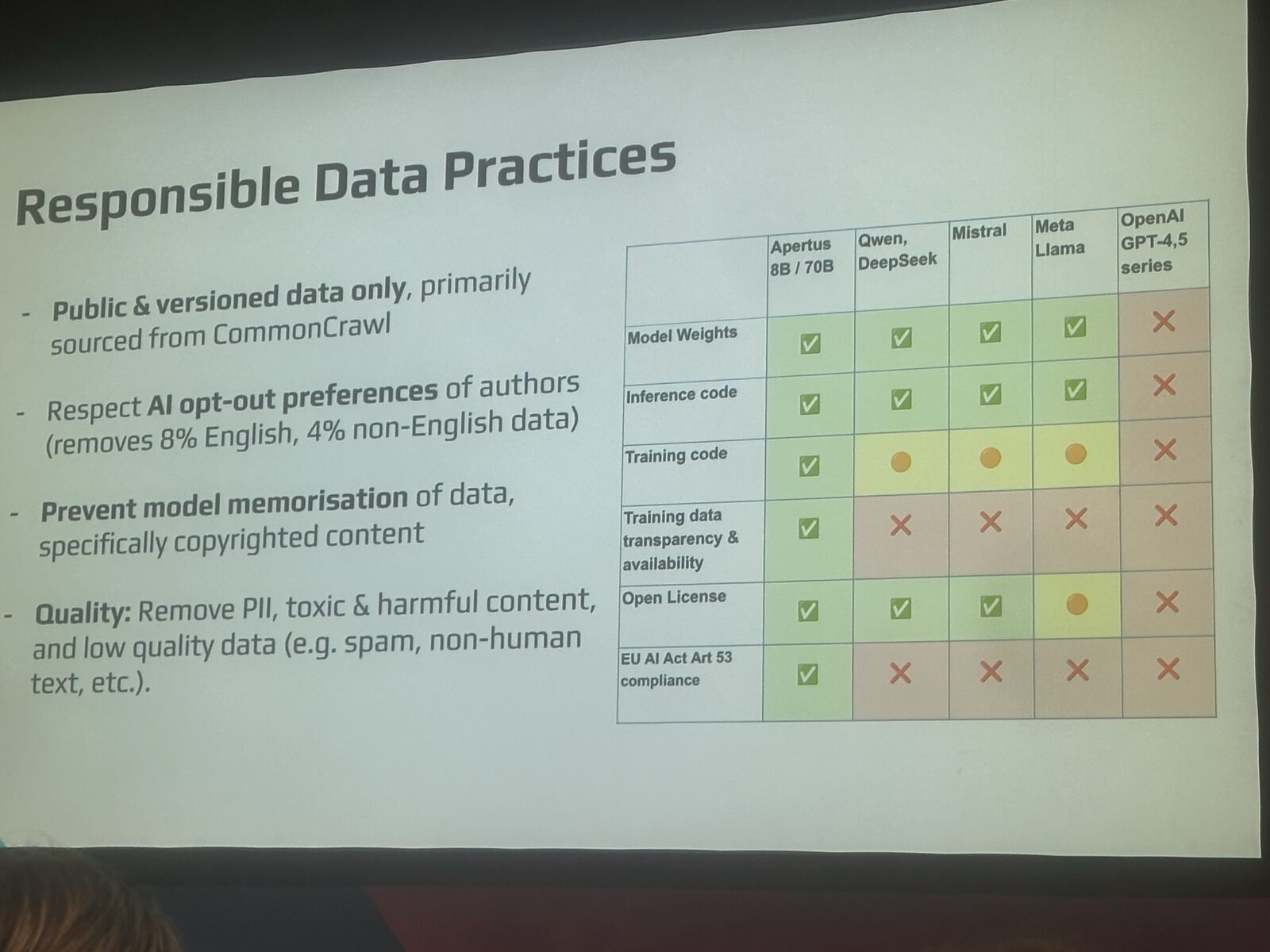
Ce n'est pas un argument marketing. L'article 53 de l'AI Act européen oblige les fournisseurs d'IA à usage général à publier «un résumé suffisamment détaillé du contenu d'entraînement». Comme l'a souligné Schlag pendant son talk: «À ma connaissance, aucun modèle closed ni open-weight ne satisfait réellement cette exigence à ce jour.» Apertus, lui, le fait.
L'équipe a aussi refusé catégoriquement de scraper du contenu piraté. Elle respecte les signaux AI opt-out (les directives IA façon robots.txt), ce qui leur coûte environ 8 % des données d'entraînement en anglais et 4 % des données non anglophones. Un prix qu'ils étaient heureux de payer. Ils sont allés plus loin: Schlag a décrit une méthode explicite anti-mémorisation dans le pipeline d'entraînement, pour que le modèle ne puisse pas restituer les passages protégés par le droit d'auteur qu'il a vus pendant l'entraînement. Aucun des grands labos closed ne publie quoi que ce soit de comparable.
Le moment suisse allemand
Voici la partie du talk qui comptait le plus pour les utilisateurs et utilisatrices de Helvetra.
Apertus 1 est sorti en septembre 2025. Le premier passage de post-training (le fine-tuning supervisé qui apprend au modèle de fondation à se comporter de manière conversationnelle) contenait zéro donnée en suisse allemand. Le modèle refusait simplement de parler suisse allemand, faute d'en avoir vu pendant l'instruction tuning.
Et puis, dans les mots de Schlag lui-même:
«Parce que nous avons une base multilingue très forte et beaucoup d'autres langues alémaniques dans les données d'entraînement, il a fallu à un doctorant peut-être une journée pour assembler quelques milliers d'exemples conversationnels en suisse allemand, dont la moitié générés de façon synthétique, pour faire passer la performance de pratiquement zéro à, soyons honnêtes, 50–40 %. Donc ce n'est évidemment pas extraordinaire, mais l'extraordinaire est jusqu'où c'est allé avec si peu de travail.»
Relisez attentivement. Un doctorant. Une journée. Quelques milliers d'exemples, dont la moitié synthétiques. De zéro à environ 40 % de performance en suisse allemand.
Schlag a été honnête: 40 % n'est pas encore exceptionnel. Mais c'est la trajectoire qui compte. Un modèle de fondation assez puissant pour faire monter une langue peu dotée à ce niveau en une seule journée de post-training, c'est un modèle qui continuera de bien s'améliorer en suisse allemand au fur et à mesure que l'équipe y investit. Et elle le fait. Apertus 1.5 est en post-training en ce moment même; Apertus 2 est conçu à une échelle bien plus grande.
Chaque fois qu'Apertus s'améliore, Helvetra s'améliore automatiquement. C'est le contrat que nous avons signé en choisissant un modèle suisse fully open comme moteur.
Ce qui arrive ensuite
Le déploiement tessinois que Schlag a mentionné en passant mérite un regard plus attentif, parce que c'est l'usage le plus concret d'Apertus dans le secteur public à ce jour. Selon CSCS (mars 2026), le Centro sistemi informativi (CSI) du canton, rattaché au Département des finances et de l'économie, déploie un outil de traduction interne construit sur Apertus par une startup affiliée à l'USI appelée Artificialy, cofondée par Luca Gambardella (professeur d'IA à l'Università della Svizzera italiana). Une phase de test avec environ 100 employés cantonaux démarre dans les semaines à venir. Fait notable: CSCS rapporte qu'Apertus 8B a atteint un score de benchmark de 94 % après fine-tuning sur cette tâche de traduction spécifique. Un repère utile sur la performance du plus petit modèle Apertus une fois ciblé sur une charge de travail réelle.
Deux éléments concrets de la roadmap sont ressortis du talk:
Apertus 1.5 est en cours d'entraînement au moment où nous écrivons. Il s'agit d'un pre-training continu du précédent checkpoint avec des capacités d'entrée image et audio (la vision est mature, l'audio plus expérimental pour l'instant), et d'un pipeline de reinforcement learning pour le raisonnement, le code et l'utilisation d'outils. Schlag était visiblement enthousiasmé par les premiers résultats vision, et l'équipe en partagera plus dès que ce sera prêt.
Apertus 2 est une ambition plus large: combler l'écart avec les plus grands modèles open-weight, qui se situent désormais entre 500 milliards et mille milliards de paramètres. L'actuel Apertus 70B a été délibérément conçu pour égaler le Llama 3 70B original, en preuve de capacité. L'équipe veut maintenant voir jusqu'où elle peut aller sur le supercalculateur Alps du CSCS (le plus grand cluster AI-ready opéré par une institution publique au monde) tout en restant dans les standards de transparence qu'elle s'est fixés.
Pourquoi nous restons sur Apertus

Nous avons fait le même pari à notre échelle. Helvetra est ancrée à un seul modèle, Apertus, pour les mêmes raisons que Schlag a listées. Les données restent en Suisse, l'historique d'entraînement est reproductible, l'alignement est transparent, et le modèle est gouverné par des institutions publiques suisses, pas par des actionnaires américains. Nous ne prévoyons pas de proposer un «sélecteur de LLM» ni de basculer en douce vers le moins cher du trimestre. Plus de détails sur ce pari ici.
Le compromis est honnête. Apertus 1 a des lacunes, en particulier sur le suisse allemand. Nous les sentons quand nous traduisons, vous les sentez quand vous lisez le résultat. Mais la conférence sur le Gurten ce mois-ci a été un rappel fort que l'écart se réduit, vite, en public, par une équipe qui nous dit exactement comment elle s'y prend. La prochaine fois qu'Apertus sortira, Helvetra sortira avec lui.
Ressources
- Page du projet Apertus: apertvs.ai (anciennement apertus-ai.org)
- Swiss AI Initiative (ombrelle): swiss-ai.org
- Apertus sur Hugging Face: huggingface.co/swiss-ai
- Apertus sur GitHub: github.com/swiss-ai
- La page du talk: Uphill Conf, keynote Apertus
- Uphill Conf 2026: uphillconf.com
- L'infrastructure: supercalculateur CSCS Alps
- Le déploiement tessinois: CSCS: Apertus powers in-house AI translation for Ticino (mars 2026)