A developer conference on the Gurten
Uphill Conf 2026 took place on 7–8 May at the Gurten, above Bern. Per the conference's own framing, the event is tailored to software developers and focused on practical AI/ML in production: building AI-native products, securing LLM applications, agentic systems, cost-efficient inference. This year's programme included talks from Google DeepMind, AWS, Hugging Face, and IBM Research, alongside the keynote we came for.
Apertus is the Swiss-built, fully-open large language model that powers every translation Helvetra produces. When the project's co-lead announces what's coming next, we listen.
The keynote
On Friday morning, Imanol Schlag, AI Research Scientist at the ETH AI Center and co-lead of the Apertus project, opened the day with "Apertus: Democratizing Open and Compliant LLMs For Global Language Environments" (talk page).
It was the kind of talk that pulls everything together in 30 minutes. What Apertus is, why it's structured the way it is, where it sits in the global landscape, and what's coming next. The slides below are from the actual session.

Why "fully open" is not just a slogan
The distinction matters. An open-weight model lets you download the file and run it on your own hardware: useful, but you still don't know what it was trained on, who curated the data, how it was aligned. A fully open model publishes all of it. The training data and the pipeline to reproduce it, the training code, model checkpoints throughout training, and a 100+ page technical report. The Apertus GitHub organisation hosts the lot.
Schlag put this in concrete terms with a comparison table that's worth reproducing:
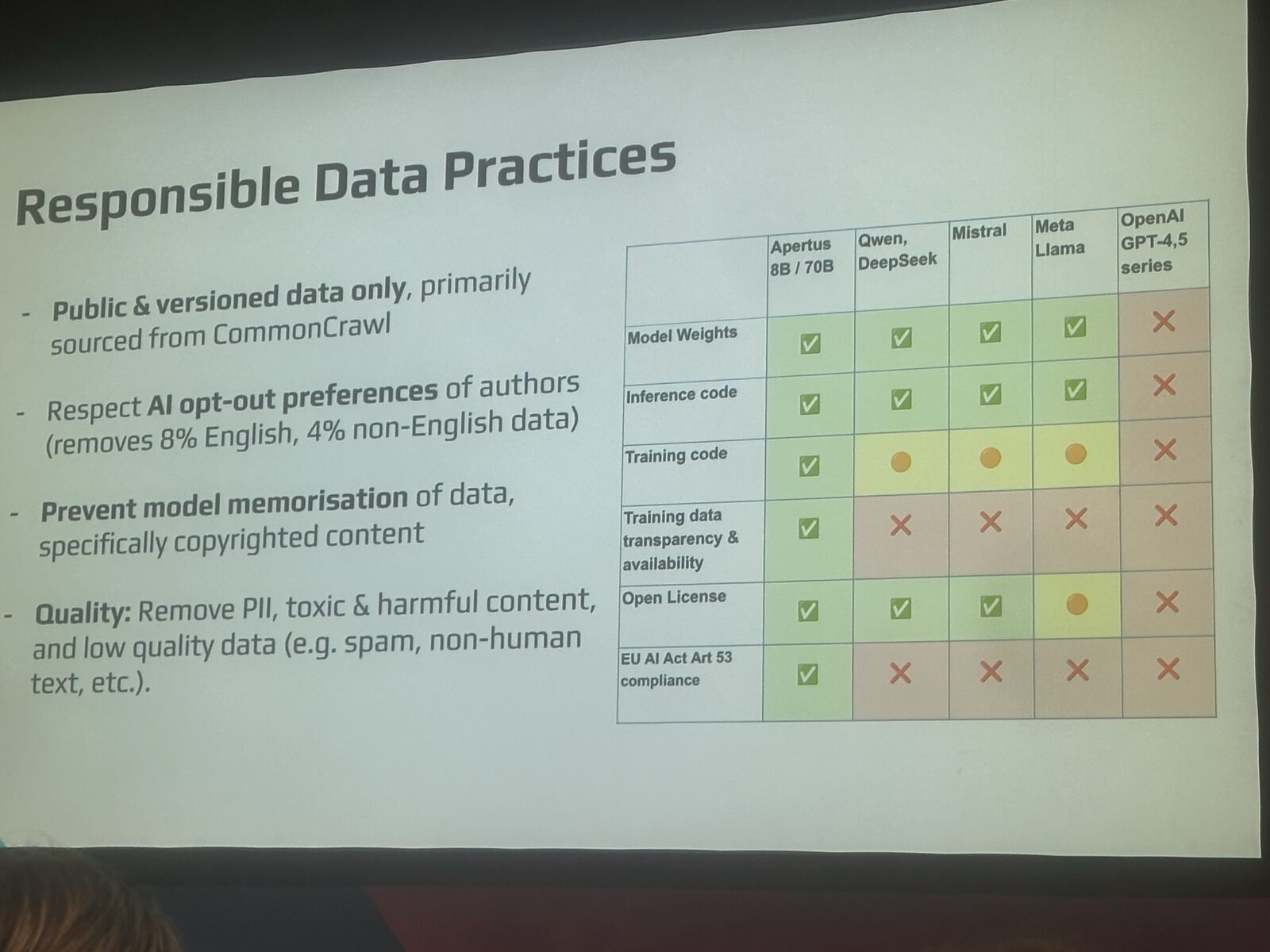
That's not a marketing claim. Article 53 of the EU AI Act requires general-purpose AI providers to publish "a detailed summary of the training content". As Schlag pointed out in his talk: "so far I know of no closed or open weight model that actually fulfills this requirement." Apertus does.
The team also categorically refused to scrape pirated content. They respect AI opt-out signals (the robots.txt-style AI directives), which costs them about 8% of English training data and 4% of non-English data. A price they were happy to pay. They went further: Schlag described an explicit anti-memorisation method in the training pipeline so the model can't regurgitate copyrighted passages it saw during training. None of the big closed labs publishes anything comparable.
The Swiss German moment
Here's the part of the talk that mattered most for Helvetra users.
Apertus 1 was released in September 2025. The first post-training pass (the supervised fine-tuning that teaches the foundation model how to behave conversationally) included zero Swiss German data. The model would simply refuse to speak Swiss German because it had barely seen any during instruction tuning.
And then, in Schlag's own words:
"Because we have such a strong multilingual foundation and lots of other Alemannic languages in the training data, it took a PhD student maybe a day to put together a few thousand Swiss German conversational examples, half of them actually synthetically generated, to bring the performance from basically zero to, let's be honest, 50–40%. So it's not amazing of course, but the amazing thing is how far it got with the little work that we had to put into."
Read that carefully. One PhD student. One day. A few thousand examples, half of them synthetic. Zero to roughly 40% Swiss German performance.
Schlag was honest: 40% isn't amazing yet. But the trajectory is the point. A foundation model strong enough to pick up an under-resourced language to that level on a single day of post-training is a foundation model that will keep getting much better at Swiss German as the team puts more effort in. And the team is. Apertus 1.5 is in post-training right now; Apertus 2 is being designed at a much larger scale.
Every time Apertus improves, Helvetra improves automatically. That's the deal we signed up for when we chose a fully-open Swiss model as our engine.
What's coming next
The Ticino deployment Schlag mentioned in passing is worth a closer look, because it's the most concrete public-sector use of Apertus to date. According to CSCS (March 2026), the canton's Computer Systems Centre (Centro sistemi informativi, CSI), inside the Department of Finance and Economy, is rolling out an in-house translation tool built on Apertus by a USI-affiliated startup called Artificialy, co-founded by Luca Gambardella (Professor of AI at Università della Svizzera italiana). A test phase with around 100 cantonal employees is starting in the coming weeks. Notably, CSCS reports that Apertus 8B reached a 94% benchmark score after fine-tuning for the specific translation task. A useful data point on how the smaller Apertus model performs when targeted at a real workload.
Two concrete roadmap items came out of the talk:
Apertus 1.5 is being trained as we write this. It's a continued pre-training of the previous checkpoint with image and audio input capabilities (vision is mature, audio more experimental for now), and a reinforcement-learning pipeline for reasoning, code, and tool use. Schlag was visibly excited about preliminary vision results, and they'll share more when ready.
Apertus 2 is bigger ambition: closing the gap with the largest open-weight models, which now sit between 500 billion and a trillion parameters. The current Apertus 70B was deliberately designed to match the original Llama 3 70B as a proof of capability. The team now wants to see how big they can go on CSCS's Alps supercomputer (the largest public-institution AI-ready compute in the world) while staying within the transparency standards they set for themselves.
Why we're staying with Apertus

We've made the same bet at our scale. Helvetra is anchored to one model, Apertus, for the same reasons Schlag listed. The data residency stays in Switzerland, the training story is reproducible, the alignment is transparent, and the model is governed by Swiss public institutions, not American shareholders. We don't plan to offer an "LLM picker" or quietly swap to whatever is cheapest this quarter. More on that bet here.
The trade-off is honest. Apertus 1 has gaps, especially on Swiss German. We feel them when we translate, you feel them when you read the output. But the talk on the Gurten this month was a strong reminder that the gap is closing, fast, in public, by a team that's telling us exactly how they're doing it. The next time Apertus ships, Helvetra ships with it.
Resources
- Apertus project home: apertvs.ai (formerly apertus-ai.org)
- Swiss AI Initiative (umbrella): swiss-ai.org
- Apertus on Hugging Face: huggingface.co/swiss-ai
- Apertus on GitHub: github.com/swiss-ai
- The talk page: Uphill Conf, Apertus keynote
- Uphill Conf 2026: uphillconf.com
- The infrastructure: CSCS Alps supercomputer
- The Ticino deployment: CSCS: Apertus powers in-house AI translation for Ticino (March 2026)